One of the most persistent questions in my customer interviews has been simple:
Will my data be used to train AI?
Not cloud security in the traditional sense. AI data security is one of the biggest concerns for teams adopting AI tools.
That concern is justified.
More engineers, researchers, and operators are using tools like ChatGPT, Claude, and Gemini in their daily work. Teams are using AI to summarize documents, analyze technical data, write code, generate reports, and accelerate decisions. But not all AI usage comes with the same level of privacy, governance, or deployment control.
That is where AI privacy tiers become important.
Optional cookies required for the embedded video
The on-page player uses a third-party YouTube embed. Accept optional cookies to load the video here, or open it directly on YouTube instead.
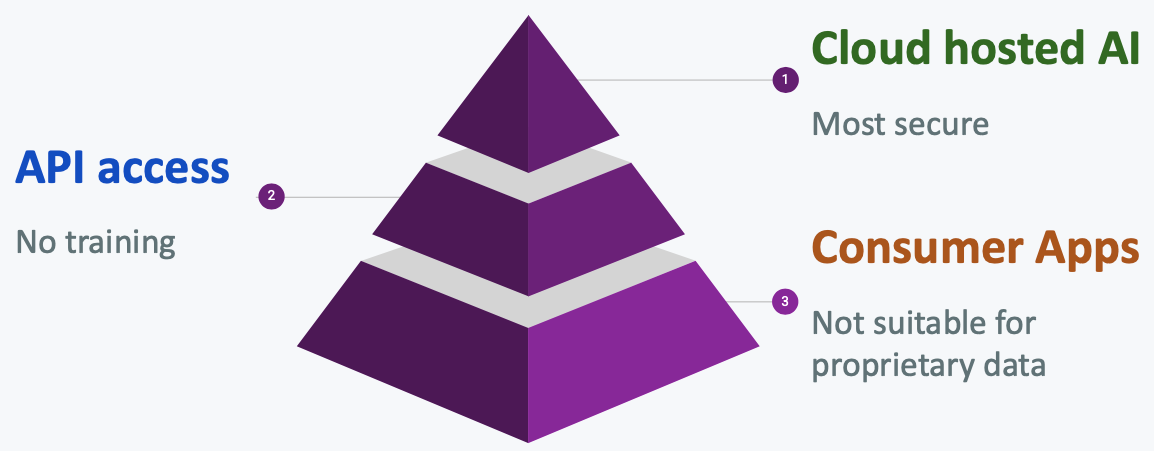
In practice, there are three broad ways teams access modern AI systems:
- Consumer AI apps
- API access
- Cloud-hosted enterprise AI
Each comes with a different tradeoff between convenience, privacy, and control. Understanding the difference is especially important if your team works with proprietary data, customer information, manufacturing data, or sensitive R&D workflows.
Why this question keeps coming up
AI adoption is moving faster than most enterprise security conversations.
A team might start with a simple workflow: paste a document into ChatGPT, ask Claude to summarize a meeting, or use Gemini to organize technical notes. These tools are incredibly powerful and easy to use, so adoption happens naturally.
But once AI becomes part of a real business workflow, the questions change.
Leaders begin to ask:
- Where does the data actually go?
- Can prompts or outputs be retained?
- Is this data used to improve the model?
- Who controls access?
- Can the model run inside our cloud environment?
- What is appropriate for non-confidential work versus sensitive IP?
These are no longer edge-case questions. They are now central questions for any team trying to use AI responsibly.
The short answer: not all AI access models are the same
When people ask whether their data will be used to train AI, they are often asking a broader question:
The answer depends heavily on how the model is accessed.
A consumer AI app, an API integration, and a cloud-hosted enterprise deployment may all involve powerful foundation models, but they are not equivalent from a privacy, governance, and deployment perspective.
That difference is often misunderstood.
The three AI privacy tiers
Tier 3: Consumer AI apps
This is the most familiar category.
Examples include:
- ChatGPT
- Claude
- Gemini
- other browser-based AI assistants
Consumer AI apps are the easiest way to get started. They are fast, intuitive, and often the best entry point for experimentation. For brainstorming, writing assistance, summarization, and general research, they can be extremely useful.
But they also tend to offer the least control over governance and deployment.
That does not mean they are inherently unsafe. It means they are usually not the right default choice for sensitive business workflows unless the product tier and policy explicitly match your needs.
Best for
- ✓ Learning and experimentation
- ✓ Non-confidential writing and ideation
- ✓ Lightweight research support
- ✓ Early exploration of use cases
Poor default for
- ✗ Proprietary algorithms
- ✗ Customer-confidential data
- ✗ Manufacturing data
- ✗ Sensitive R&D workflows
- ✗ Regulated environments

Tier 2: API access
The second tier is using models through an API.
Examples include:
- OpenAI API
- Anthropic API
- Gemini API
This is where many startups and software teams move once AI becomes part of a product or internal workflow.
API access typically gives teams stronger privacy guarantees and more operational control than consumer apps. It also gives teams the ability to build their own interfaces, logging, permissions, and business logic around AI usage.
This tier is often appropriate for:
- SaaS products
- Internal copilots
- Workflow automation
- Secure but lightweight AI features
It still relies on external model infrastructure, so it is not the highest-control option. But for many teams, this is the point where AI becomes operationally useful without requiring a full enterprise cloud deployment.
Tier 1: Cloud-hosted enterprise AI
The third tier is cloud-hosted enterprise deployment.
Examples include:
- Vertex AI
- AWS Bedrock
- Azure OpenAI
- enterprise deployments integrated with platforms like Databricks or Snowflake
This is the tier most aligned with enterprise governance and sensitive production use cases.
Instead of relying on a consumer interface or a simple API call alone, teams deploy and govern AI within a broader cloud and data architecture. This usually allows stronger alignment with security controls, data policies, identity systems, logging, compliance processes, and infrastructure boundaries.
This tier is often the best fit for:
- Enterprise AI systems
- Proprietary manufacturing workflows
- Regulated industries
- Sensitive R&D and analytics environments
- Customers who require stronger control postures
The tradeoff is complexity.
Cloud-hosted deployments typically require more setup, more architecture work, and closer coordination between engineering, security, and IT teams. But they also provide the strongest path for responsible AI adoption in environments where data sensitivity is high.

How the tiers compare
A useful mental model is this:
- Consumer AI apps maximize convenience
- API access balances convenience and control
- Cloud-hosted AI maximizes control

| Access model | Ease of use | Privacy / data control | Infrastructure complexity | Best fit |
|---|---|---|---|---|
| Consumer AI apps | High | Lower | Low | Brainstorming, lightweight non-confidential work |
| API access | Medium to high | Medium to high | Medium | Product workflows, internal tools, secure automation |
| Cloud-hosted enterprise AI | Medium | Highest | High | Sensitive data, enterprise deployments, regulated or IP-heavy environments |
Which tier is right for your team?
There is no single answer for every company.
The right choice depends on:
- the sensitivity of your data
- the maturity of your security requirements
- whether the workflow is experimental or production-facing
- how much engineering and infrastructure support you have
A practical way to think about it is:
- Use consumer apps for low-risk exploration.
- Use APIs when AI becomes part of a real workflow, product, or repeated internal process.
- Use cloud-hosted enterprise AI when the workflow involves sensitive business data, customer data, proprietary IP, or enterprise procurement requirements.
In many companies, all three tiers may exist at the same time. The important part is being intentional about which tier is used for which workflow.
How we think about this at Niobia AI
At Niobia AI, we believe security is a design requirement, not an afterthought.
That belief matters because our users work with technical, proprietary, and operationally meaningful data. In advanced manufacturing and battery R&D, data sensitivity is not theoretical. Teams may be working with experimental results, process data, internal know-how, customer information, and valuable IP.
That is why deployment architecture matters.
The more useful question is: What level of control does this workflow require, and what deployment model matches that need?
For lighter-weight use cases, secure API-based access may be appropriate. For more demanding environments, cloud-hosted enterprise deployments provide a stronger control posture.
The important thing is to match the deployment model to the sensitivity of the work.

Frequently asked questions
Final takeaway
The question "Will my data be used to train AI?" is important, but it is only part of the bigger picture.
The more complete question is:
How much privacy, control, and governance does this workflow actually need?
That is the right lens for evaluating AI deployments.
Consumer AI apps, APIs, and cloud-hosted enterprise AI all have a place. The key is understanding the tradeoffs and choosing the right tier for the job.
As AI becomes part of more real-world workflows, this distinction will only become more important.